
This is one of the popular data science interview questions which requires one to create the ROC and similar curves from scratch, i.e., no data on hand. For the purposes of this story, I will assume that readers are aware of the meaning and the calculations behind these metrics and what they represent and how are they interpreted. Therefore, I will focus on the implementation aspect of the same. We start with importing the necessary libraries (we import math as well because that module is used in calculations)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import math
The first step is to generate the ‘actual’ data of 1s (bads) and 0s (goods), because this will be used to calculate and compare the model accuracy via the aforementioned metrics. For this article, we will create the “actual vector” from Uniform distribution. For the subsequent and related article, we will use Binomial distribution.
actual = np.random.randint(0, 2, 10000)
The above code generates 10,000 random integers belonging to [0,1] which is our vector of the actual binary class. Now, of course we need another vector of probabilities for these actual classes. Normally, these probabilities are an output of a Machine learning model. However, here we will generate them randomly making some useful assumptions. Let’s assume the underlying model is a ‘logistic regression model’, therefore, the link function is logistic or logit.
The figure below describes the standard logistic function. For a logistic regression model, the expression -k(x-x_0) is replaced by a ‘score’. The ‘score’ is a weighted sum of model features and model parameters.
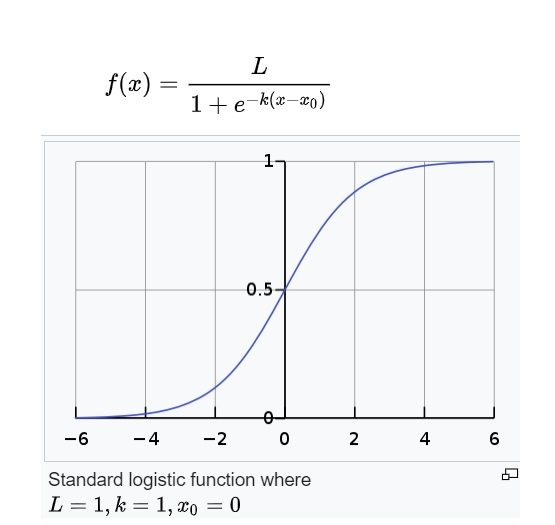
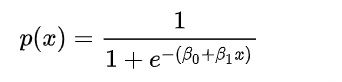
Thus, when the ‘score’ = 0, the logistic function must pass through 0.5 on the Y-axis. This is because logit(p) = log-odds(p) = log(p/(1-p)) = 0 => p = 1-p => p =0.5. Also notice that when the ‘score’ attains high positive or high negative values, the function asymptotically moves towards either 1 (bad) or 0 (good). Thus, the higher the absolute value of ‘score’ is, the higher the predicted probability is as well. But what are we scoring? We are scoring each data input present in our ‘actual vector’. Then, if we want to assume that our underlying logistic regression model is skilled, i.e., predictive; the model should assign comparatively higher scores to bads vs goods. Thus, bads should have more positive scores (to ensure that the predicted probability is close to 1) and goods should have more negative scores (to ensure that the predicted probability is close to 0). This is known as rank ordering by the model. In other words, there should be discrimination or separation between the scores and hence the predicted probabilities of bads vs goods. Since, we have seen that the score of 0 implies probability of good = probability of bad = 0.5; this would mean the model is unable to differentiate between good and bad. But since we do know that the data point will be actually either good or bad, therefore, a score of 0.5 is the worst possible score from the model. This gives us some intuition to move to the next step.
The scores can be randomly generated using the Standard Normal distribution with a mean of 0 and a standard deviation of 1. However, we want different predicted scores for bads and goods. We also want bad scores should be higher than the good scores. Thus, we use the standard normal distribution and shift its mean to create a separation between the goods and the bads.
# scores for bads
bads = np.random.normal(0, 1, actual.sum()) + 1
# scores for goods
goods = np.random.normal(0, 1, len(actual) - actual.sum()) - 1
plt.hist(bads)
plt.hist(goods)
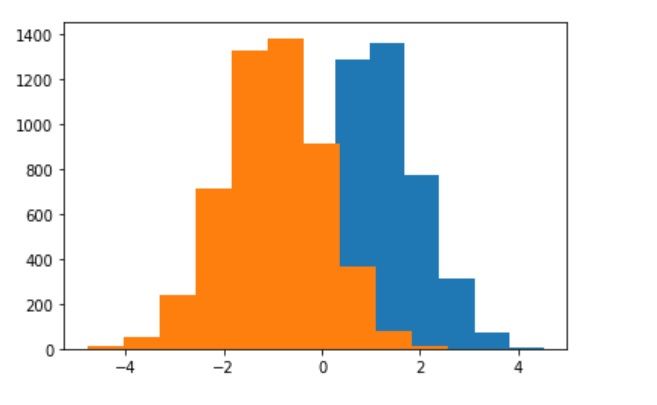
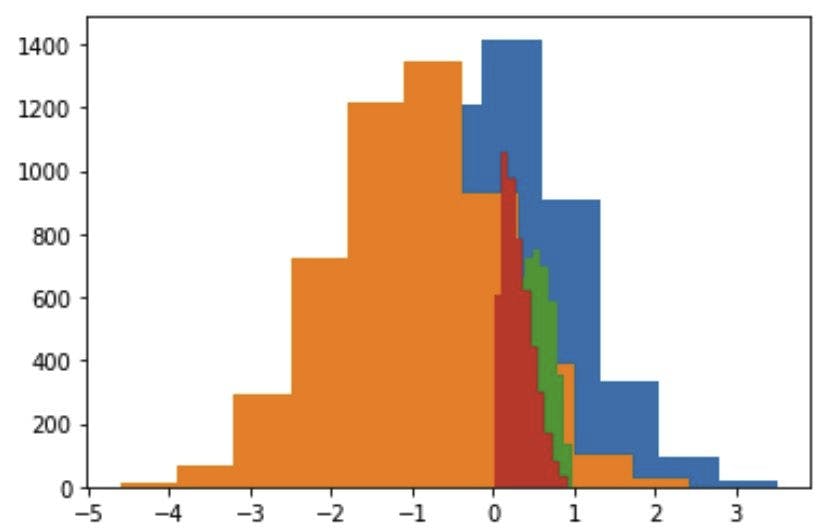
In the aforementioned code, we sampled bads scores and goods scores from two different standard normal distributions but we shifted them to create a separation between the two. We shift the bads scores (represented by the blue color in the image) by 1 towards the right and vice-versa by 1 towards the left. This ensures the following:
- The bads scores are higher than the goods scores for a substantially high (as per the visual) cases
- The bads scores have proportionately higher number of positive scores and the goods scores have proportionately higher number of negative scores
We can of course maximize this separation by increasing the ‘shift’ parameter and assign it values higher than 1. However, in this story, we won’t do that. We will explore that in the subsequent related stories. Now, let’s look at the probabilities generated by these scores.
# prob for bads
bads_prob = list((map(lambda x: 1/(1 + math.exp(-x)), bads)))
# prob for goods
goods_prob = list((map(lambda x: 1/(1 + math.exp(-x)), goods)))
plt.hist(bads_prob)
plt.hist(goods_prob)
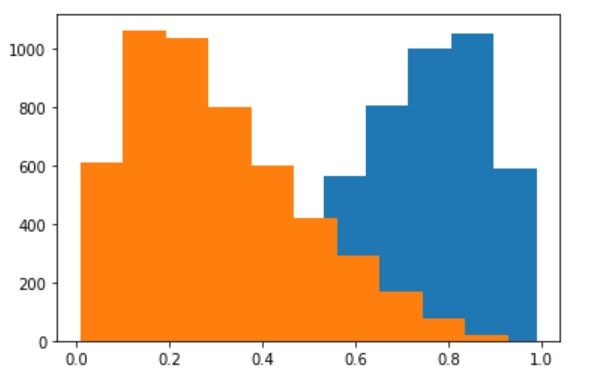
As discussed earlier, when the ‘scores’ are pushed through the logistic function, we get the probabilities. It is evident that the bad probabilities (blue color) are higher (and skewed towards 1), than the good probabilities (orange color) (and skewed towards 0).
The next step is to combine the actuals and predicted vectors into one single data frame for analysis. We assign bad probabilities where the data instance is actually bad and vice-versa
# create predicted array
bads = 0
goods = 0
predicted = np.zeros((10000))
for idx in range(0, len(actual)):
if actual[idx] == 1:
predicted[idx] = bads_prob[bads]
bads += 1
else:
predicted[idx] = goods_prob[goods]
goods += 1
actual_df = pd.DataFrame(actual, columns=['actual'])
predicted_df = pd.DataFrame(predicted, columns=['predicted'])
predicted_df = pd.concat([actual_df, predicted_df], axis = 1)
predicted_df = predicted_df.sort_values(['predicted'], ascending = False).reset_index()
predicted_df = predicted_df.drop(columns = 'predicted')
The next step is to create bins. This is because the curves that we want to generate are discrete in nature. For each bin, we calculate our desired metrics cumulatively. In other words, we generate cumulative distribution functions for the discrete random variables - goods and bads.
- The number of bins is arbitrary (we assign n_bins = 50).
- Note the use of floor function. This is because the length of the data frame may not divide equally into 50 bins. Thus, we take the floor of it and modify our code such that the last bin (50th bin) would contain the extra observations (which will be < 50).
n_bins = 50
bin_size = math.floor(len(predicted_df) / n_bins)
curve_metrics = []
We should enlist the volumes of bads and goods and bin sizes for our reference
print("number of bads:", bads)
print("number of goods:", goods)
print("number of total data points:", len(actual))
print("bin size:", len(predicted_df) / n_bins)
number of bads: 4915
number of goods: 5085
number of total data points: 10000
bin size: 200.0
Next comes the main code snippet where we make the actual calculations of the underlying metrics
for k in range(1, n_bins + 1):
if k < n_bins:
TP = predicted_df.loc[ : k*bin_size-1, "actual"].sum()
FP = k*bin_size - TP
FN = predicted_df.loc[(k*bin_size) : , "actual"].sum()
TN = len(actual) - k*bin_size - FN
cum_bads = predicted_df.loc[ : k*bin_size-1, "actual"].sum()
cum_goods = k*bin_size - cum_bads
else:
TP = predicted_df.loc[ : , "actual"].sum()
FP = len(actual) - TP
FN = 0
TN = 0
cum_bads = bads
cum_goods = goods
curve_metrics.append([k, TP, FP, TN, FN, cum_bads, cum_goods])
Notice that the for loop would run from 1 to n_bins, i.e., it leaves out one at the end. Therefore, we have n_bins + 1 as the ‘stop value’.
For k = 1 to k = n_bins-1, we make cumulative calculations of True positives, False Positives, False Negatives, True Negatives, cumulative bds and cumulative goods using the bin_size.
-
Notice that the snippet “predicted_df.loc[ : k*bin_size-1, "actual"].sum()” would run from index = 0 to index = kbin_size-1. Thus, it takes out the chunk equal to k*bin_size. Therefore, we subtract 1 from k*bin_size
-
Similarly, the snippet “predicted_df.loc[(k*bin_size) : , "actual"].sum()” would run from index = k*bin_size to the final index. Thus, if the bin is from 0 to 49 (size 50), the snipper runs from index = 50 (which is equal to bin_size) onwards
For k = n_bins, we just extend it to the final index of the dataset. Where, the snippet “predicted_df.loc[ : , "actual"].sum()” sums up all the bads as the indexing runs from index = 0 to the final index of the dataframe. We can also replace it with “TP = bads”. FN and TN are both = 0 because at the last cut-off we assign everything as ‘bad’. Therefore, there is no False Negative (actual bad) or True Negative (actual good) left. Because, the negative class does not exist when k = n_bins.
It is useful to check what does the cumulative matrix look like.
curve_metrics

Notice that for k = n_bins = 50, we have accumulated all goods (5085) and all bads (4915).
Now we are ready to make the actual calculations needed for the desired curves
curve_metrics_df = pd.DataFrame(curve_metrics, columns=["cut_off_index", "TP", "FP", "TN", "FN", "cum_bads", "cum_goods"])
curve_metrics_df["cum%bads"] = curve_metrics_df["cum_bads"] / (actual.sum())
curve_metrics_df["cum%goods"] = curve_metrics_df["cum_goods"] / (len(actual) - actual.sum())
curve_metrics_df["precision"] = curve_metrics_df["TP"] / (curve_metrics_df["TP"] + curve_metrics_df["FP"])
curve_metrics_df["recall"] = curve_metrics_df["TP"] / (curve_metrics_df["TP"] + curve_metrics_df["FN"])
curve_metrics_df["sensitivity"] = curve_metrics_df["TP"] / (curve_metrics_df["TP"] + curve_metrics_df["FN"])
# specificity is the recall on the negative class
curve_metrics_df["specificity"] = curve_metrics_df["TN"] / (curve_metrics_df["TN"] + curve_metrics_df["FP"])
- The ROC curve is a curve between cumulative bads (Y-axis) and cumulative goods (X-axis)
- The ROC curve is a curve between sensitivity (which is also cumulative bads or recall : Y-axis) and 1-specificity (X-axis)
- The Precision Recall curve is a curve between Precision (Y-axis) and Recall (which is also sensitivity or cumulative bads: X-axis)
That’s it. We have everything needed to plot our curves now.
plt.plot(curve_metrics_df["cum%goods"], curve_metrics_df["cum%bads"], label ="roc curve")
plt.xlabel("cum%goods")
plt.ylabel("cum%bads")
plt.title("ROC Curve")
plt.legend()
plt.show()
plt.plot(1 - curve_metrics_df["specificity"], curve_metrics_df["sensitivity"], label ="sensitivity specificity curve")
plt.xlabel("1 - Specificity")
plt.ylabel("Sensitivity")
plt.title("Sensitivity vs 1-Specificity Curve")
plt.legend()
plt.show()
plt.plot(curve_metrics_df["recall"], curve_metrics_df["precision"], label ="precision recall curve")
plt.xlabel("Precision")
plt.ylabel("Recall")
plt.title("Precision Recall Curve")
plt.legend()
plt.show()
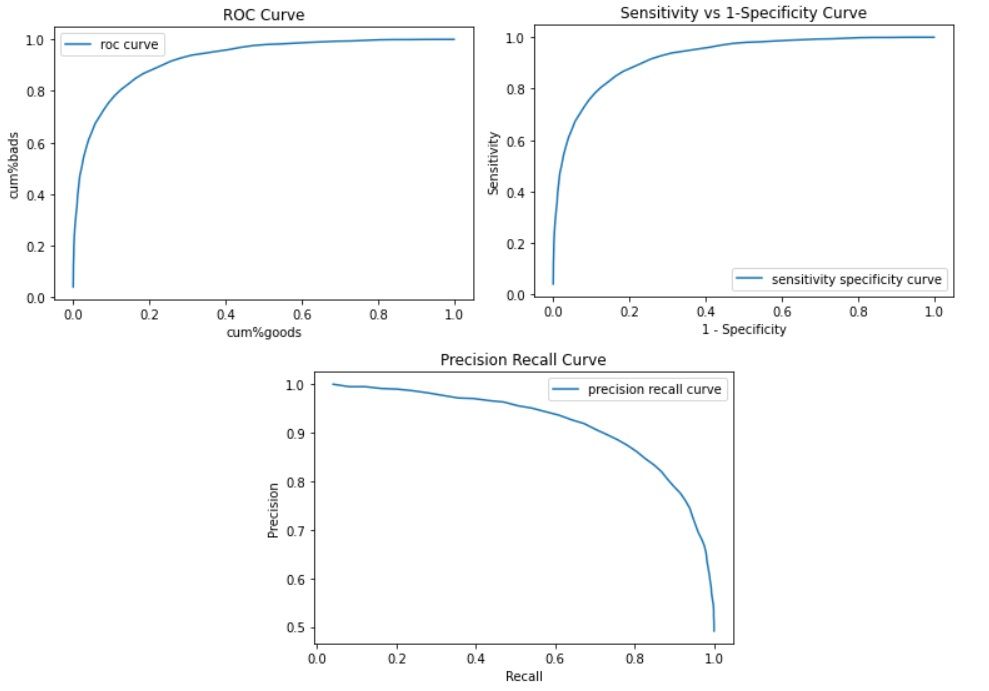
All the curves confirm the use of a highly skilled model (as we had formulated in the starting). This completes are task of creating these curves from scratch.
Food for thought - “what happens to these curves when the classes are severely imbalanced?” This will be the topic of the next story.
If you like this, then please have a look at the other stories of mine.