

Authors:
(1) Silei Xu, Computer Science Department, Stanford University Stanford, CA with equal contribution {[email protected]};
(2) Shicheng Liu, Computer Science Department, Stanford University Stanford, CA with equal contribution {[email protected]};
(3) Theo Culhane, Computer Science Department, Stanford University Stanford, CA {[email protected]};
(4) Elizaveta Pertseva, Computer Science Department, Stanford University Stanford, CA, {[email protected]};
(5) Meng-Hsi Wu, Computer Science Department, Stanford University Stanford, CA, Ailly.ai {[email protected]};
(6) Sina J. Semnani, Computer Science Department, Stanford University Stanford, CA, {[email protected]};
(7) Monica S. Lam, Computer Science Department, Stanford University Stanford, CA, {[email protected]}.
Table of Links
WikiWebQuestions (WWQ) Dataset
Conclusions, Limitations, Ethical Considerations, Acknowledgements, and References
A. Examples of Recovering from Entity Linking Errors
Abstract
While large language models (LLMs) can answer many questions correctly, they can also hallucinate and give wrong answers. Wikidata, with its over 12 billion facts, can be used to ground LLMs to improve their factuality.
This paper presents WikiWebQuestions, a highquality question answering benchmark for Wikidata. Ported over from WebQuestions for Freebase, it consists of real-world data with SPARQL annotation.
This paper presents a few-shot sequence-tosequence semantic parser for Wikidata. We modify SPARQL to use the unique domain and property names instead of their IDs. We train the parser to use either the results from an entity linker or mentions in the query. We fine-tune LLaMA by adding the few-shot training data to that used to fine-tune Alpaca.
Our experimental results demonstrate the effectiveness of this methodology, establishing a strong baseline of 76% and 65% answer accuracy in the dev and test sets of WikiWebQuestions, respectively. By pairing our semantic parser with GPT-3, we combine verifiable results with qualified GPT-3 guesses to provide useful answers to 96% of the questions in dev. We also show that our method outperforms the state-of-the-art for the QALD-7 Wikidata dataset by 3.6% in F1 score.[1]
1 Introduction
Large language models (LLMs) such as GPT-3 can answer open-domain questions without access to external knowledge or any task-specific training examples. However, LLMs are prone to hallucinate (Bang et al., 2023), while using a convincing and confident tone. This may cause significant harm as people increasingly accept LLMs as a knowledge source (Goddard, 2023; Weiser, 2023).

ion answering (KBQA) is grounded with a given knowledge base. Semantic parsing (SP) has been widely used to tackle this challenging task, where the questions are first parsed into a logical form and then executed to retrieve answers from the knowledge base. It has better interpretability than GPT-3 and other information-retrieval-based approaches (Dong et al., 2015; Miller et al., 2016; Sun et al., 2018, 2019) where answers are predicted directly.
To handle large knowledge bases, previous SPbased approaches tend to use a multi-stage pipeline of sub-tasks, starting with extracting the relevant subgraph based on entities detected in the questions (Yih et al., 2015; Luo et al., 2018). Such an approach struggles with questions that have a large search space and fails to understand questions that refer to information missing in the knowledge graph. Having to retrieve the relevant subgraphs to create the logical form conflates query resolution with semantic parsing, rendering classical query optimization inapplicable.
End-to-end seq2seq translation, on the other hand, has mainly been used on schemas of relatively small relational databases (Yu et al., 2018; Xu et al., 2020a,b) and web APIs (Campagna et al., 2017; Su et al., 2017). To handle large knowledge graphs, recent work proposed retrieving (1) information on linked entities, (2) exemplary logical forms relevant to the query (Gu et al., 2021; Ye et al., 2022), and (3) schemas as context to semantic parsing (Shu et al., 2022). Others use induction or iterative methods to generate complex logical forms (Cao et al., 2022b; Gu and Su, 2022).
1.1 Few-Shot Seq2Seq Semantic Parsing
This paper investigates how we can leverage large language models (LLMs) to create seq2seq neural semantic parsers for large knowledge bases such as Wikidata.
Pretrained with the internet corpora, LLMs are already familiar with the syntax of formal query languages such as SQL (Hu et al., 2022; Poesia et al., 2022; Li et al., 2023; An et al., 2023; Nan et al., 2023; Arora et al., 2023). When given simple SQL schemas, they can perform zero-shot semantic parsing of simple natural language queries into formal queries.
Unlike Freebase, the KB used in most of the KBQA semantic parsing research, Wikidata does not have a pre-defined schema, making it a much harder problem. It has 150K domains, 3K applicable properties, and 107M entities, each of the properties and entities are uniquely identified with PIDs and QIDs, respectively. While zero-shot LLMs can generate SPARQL queries for the easiest and most common questions, they do not know all the PIDs and QIDs, and nor is it possible to include them in a prompt.
This paper presents WikiSP, a few-shot sequence-to-sequence semantic parser for Wikidata that translates a user query, along with results from an entity linker, directly into SPARQL queries. To handle the 100M+ entities in Wikidata, we train the parser to use either the entity linker results or a mention in the query; to handle the 150K domains and 3K applicable properties, we modify SPARQL to use domain and property names instead of their unique QIDs and PIDs, respectively. We fine-tune a LLaMA (Touvron et al., 2023) with a few-shot training set along with the instructions used to finetune Alpaca (Taori et al., 2023).
1.2 A New Dataset: WikiWebQuestions
Most of the widely-used high-quality benchmarks for KBQA are based on Freebase (Bollacker et al., 2008) which has been shut down since 2015. With outdated knowledge, it is hard to compare the results with modern LLMs such as GPT-3, since answers have changed over time for most of the questions. Wikidata, despite being the largest and most popular knowledge base nowadays, has very few datasets annotated with SPARQL queries; they are either extremely small (Usbeck et al., 2017) or synthetic (Saha et al., 2018).
We migrated the popular WebQuestionsSP (Yih et al., 2016) benchmark from Freebase to Wikidata, with updated SPARQL and up-to-date answers from the much larger Wikidata.
1.3 Complementing Large Language Models
Trained on Wikipedia and all of the internet, LLMs can answer many questions directly. Unfortunately, the user cannot tell if the answers are correct, thus requiring them to fact-check every answer.
Unlike humans, GPT-3 always sounds definitive even when they are wrong by providing specific and plausible facts. For example, on the question “what is the biggest country in Europe by population?”, GPT-3 answers “Germany”, when the answer is “Russia”. Or, on the question, “where does the name Melbourne come from?” GPT-3 answers “Melbourne comes from the Latin word ‘melburnum’ meaning ‘blackburn’ or ‘blackbird’.”, but in reality, Melbourne is named after William Lamb, 2nd Viscount Melbourne. It is not possible to tell when GPT-3’s answers are wrong, and every answer needs to be fact-checked.
Semantic parsers can be used to complement LLMs as they are interpretable; their results are grounded in Wikidata, which we assume to be correct. It is possible for semantic parsers to misunderstand a query, but by providing the answer in the context of the query, the user can spot the error.
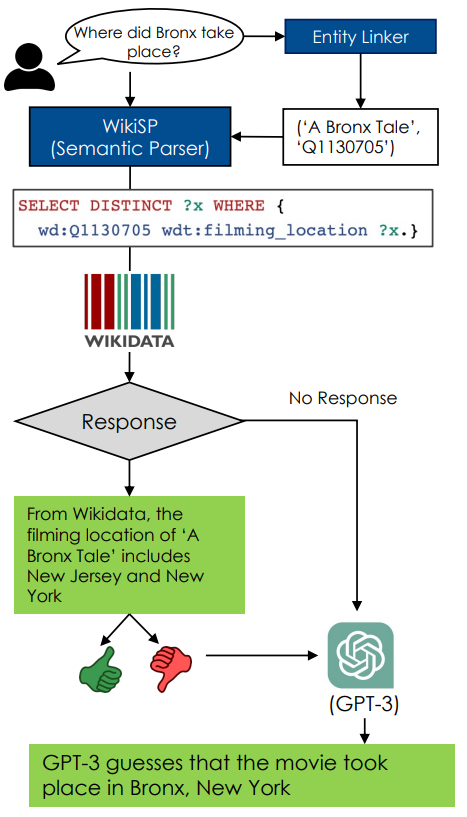
We propose getting the best of both worlds by answering the question with WikiSP if possible. Otherwise, we report GPT-3’s guesses by prefacing it with: “GPT-3 guesses that” (Figure 1). In this way, the user can have full confidence with the answers from the former, while also benefiting from the latter. It is easier for users to fact-check an answer than trying to find the answer.
1.4 Contributions
WikiWebQuestions, a high-quality semantic parsing dataset for Wikidata, migrated from the popular WebQuestions dataset for Freebase.
WikiSP, a few-shot Seq2Seq semantic parser by fine-tuning LLaMA with a few shot training set. We improve the learnability of SPARQL queries by replacing the IDs of properties and domains with their unique names; we tolerate errors in entity linking by accepting mentions in the queries as entities. We establish a first, strong baseline of 76% and 65% answer accuracy for the dev set and test set of our new WikiWebQuestions benchmark, respectively. We also demonstrate that our method surpasses the state of the art for QALD-7 wikidata set by 3.6% in F1 score.
We improve GPT-3’s trustworthiness by first returning interpretable results from semantic parser and backing it up with GPT-3 guesses. WikiSP can provide verifiable results for WikiWebQuestions 76% of the time and improves the guesses by GPT3, resulting in errors only 4% of the time (Figure 2).
This paper is available on arxiv under CC 4.0 license.
[1] Code, data, and model are available at https://github.com/stanford-oval/ wikidata-emnlp23